A common problem when teaching a machine translation system is domain mismatches. The bigger the training data, the lesser probability of errors, but still, as the systems operate at sentence-level, they cannot focus on broader coherence, e.g. lexical choice.
For this year’s WMT News Translation Task we prepared a test suite based on audit reports and one special type of document: a sublease agreement. The test suite consisted of 10 multi-language reports (from 5 languages) translated by translation agencies and corrected by authorized auditors. The outcome was a tri-parallel test set (Czech-English-German) segmented and aligned to sentences, and then manually revised.
These files were given to all primary MT systems participating in the News Translation Task. English → Czech and English ↔ German systems were supervised (trained on genuine parallel texts), whereas Czech ↔ German systems were trained on monolingual sources and target texts with a minor occurrence of parallel development sets.
There was both automatic and manual evaluation of the results. For English-to-Czech we can generally say the specific domain of audit reports does not differ much from the general observations made in the main News Translation Task; the better systems are very close to the human performance. English → German was of lower quality according to the human annotator than according to the automatic one. In case of German → English, their opinions agreed.
The extra added document was from the category of agreements – namely a sublease agreement, the English version of which was a non-professional translation from Czech.
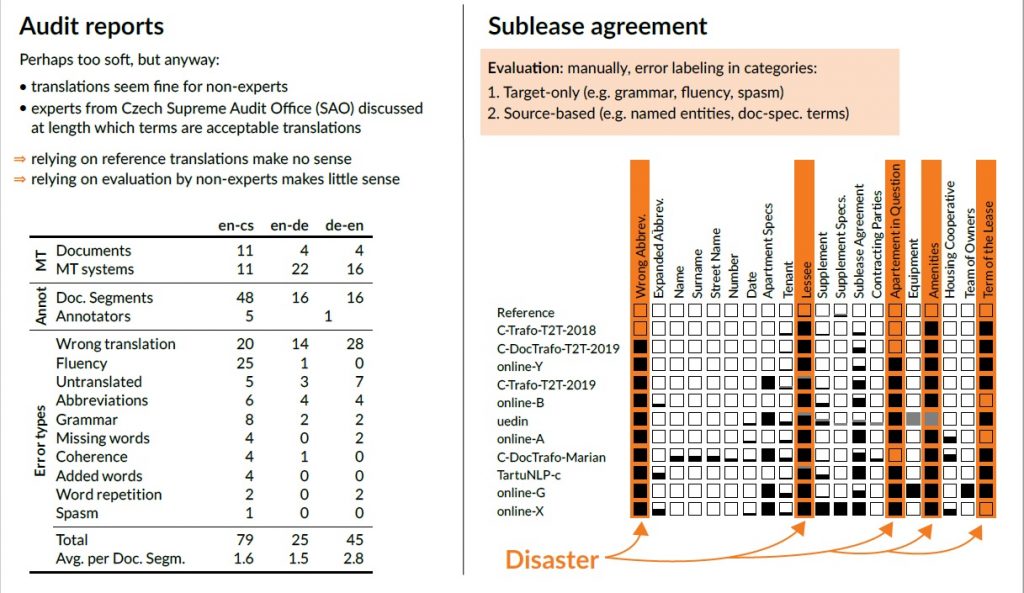
The MT system was often free to choose from several translation options of a term (same as a human translator is). At the same time, a very important criterion was whether the translation of each of the terms was consistent throughout the document and also whether it did not clash with other choices. Terms „sublease“, „tenant“ and „lessee“ have more possible translations to Czech + there is an issue with their gender variants. The inconsistency and wrong selection of the adequate term were here marked as a serious error as they are key for the agreement. If a system chooses from the possible variants the same word for two different terms in English (e.g. “nájemce”, actually possible for both “tenant” and “lessee”), the agreement suddenly does not make any sense. Should the both terms appear in an agreement, “lessee” needs to be translated as “podnájemce” to avoid confusion. The reference human translation made only one error by using the wrong term while all the other systems cause a term clash (using the same term for both parties) in half of the cases. This, in fact, corresponds to all the mentions of the second party and all these translations by all the systems are thus completely wrong.
Despite the fact that the participating MT systems were trained for a rather general domain of news articles, many of them perform very well on general terms. An important observation in our study was that a thorough domain knowledge is necessary to assess the correctness of the translation, esp. in terms of lexical choices, and that the reference translations are insufficient for the task.
You can read the full article here: http://www.statmt.org/wmt19/pdf/53/WMT55.pdf