Every computational project naturally requires energy. Here we do not speak of the mental energy of the
Therefore, there are advocates for considering research efficiency as an important evaluation criterion for future research. This should, among others, help to make AI greener and more inclusive.
Recent trends stressed the importance of state-of-the-art results. The focus is on accuracy measures and
But how to establish the “colour” of the research in question? Schwartz, Dodge, Smith, and Etzioni (2019) suggest introducing a simple metric that could make AI research greener, more inclusive, and even more cognitively plausible. Anyway, in the global situation of today, any researcher should be taking the ecological dimension of their work into account.
Obviously, larger models have stronger performance and valuable scientific contribution. However, this is a vicious circle because the research will require more and more research volume.
See the main contributions of papers at major conferences in 2018/2019:
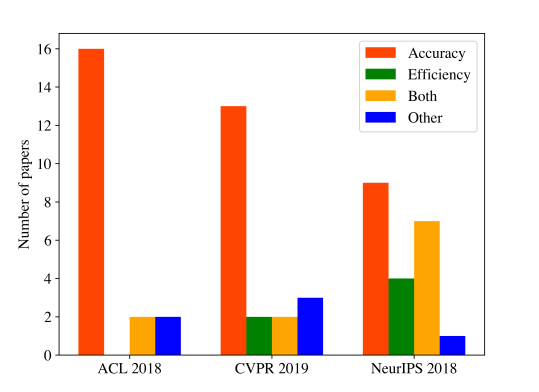
The research inefficiency problem also affects the area of natural language processing; see the very red bar of ACL 2018, the top conference in the field. In a recent paper, Kocmi and Bojar (September 2019) present a simple transfer learning method to recycle already trained machine translation models for different language pairs with no need for modifications in model architecture, hyper-parameters, or vocabulary. Their approach requires only one pretrained model for all transferring to all various languages’ pairs. Most works on transfer learning so far have relied on a shared vocabulary between parent and child models. Bojar and Kocmi propose a novel view on re-using already trained models without the need to prepare shared vocabulary in advance, i.e. saving time and energy. The approach leads to better performance and faster convergence speed compared to training the model from scratch; moreover, it is useful even for language pairs with both different languages than the parent model’s language pair.
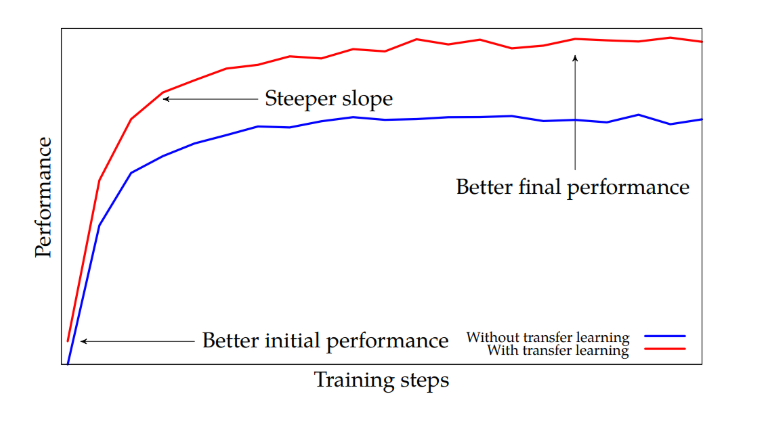
Their method is “cold-start”, meaning that the child model works with exactly the same vocabulary as the parent model has, never mind any specifics of the child languages. Therefore, any model can be used as a parent, even if it was trained by someone else and its original training data cannot be accessed. The scenario relies on segmenting child words into

In order to document that the method is general, not restricted to the laboratory setting, and replicable, authors did not train the parent model themselves. Instead, they recycled a model downloaded from the web. This leads to another saving.
The technique is simple, effective, and applicable to models trained by others, which makes it more likely that these experimental results will be replicated in practice. The cold-start scenario of transfer learning could be used instead of random initialization without any performance or speed losses. The approach of Kocmi and Bojar (2019) can be seen as an exciting option for improving the reproducibility of NMT experiments. Instead of training from randomly initialized models (= energetically demanding, being on the Red AI side), NMT papers could start from a published well-known baselines (= already done, not consuming extra energy, inclining to the Green AI side).
Let’s repeat that choosing green AI is a valuable option not an exclusive mandate, but in the end, it is always fine to have a space-, time- and data-efficient project. Still, every researcher
Download the whole article by Kocmi and Bojar here: https://arxiv.org/abs/1909.10955
Read the article about Green AI here: https://arxiv.org/pdf/1907.10597.pdf