It is widely known that translating sentences in isolation is suboptimal because the correct translation may rely on context beyond the current sentence. One challenge for the development of document-level machine translation systems is to quantify the translation errors stemming from lack of context, and measure to what extent document-level models succeed in reducing the number of such errors.
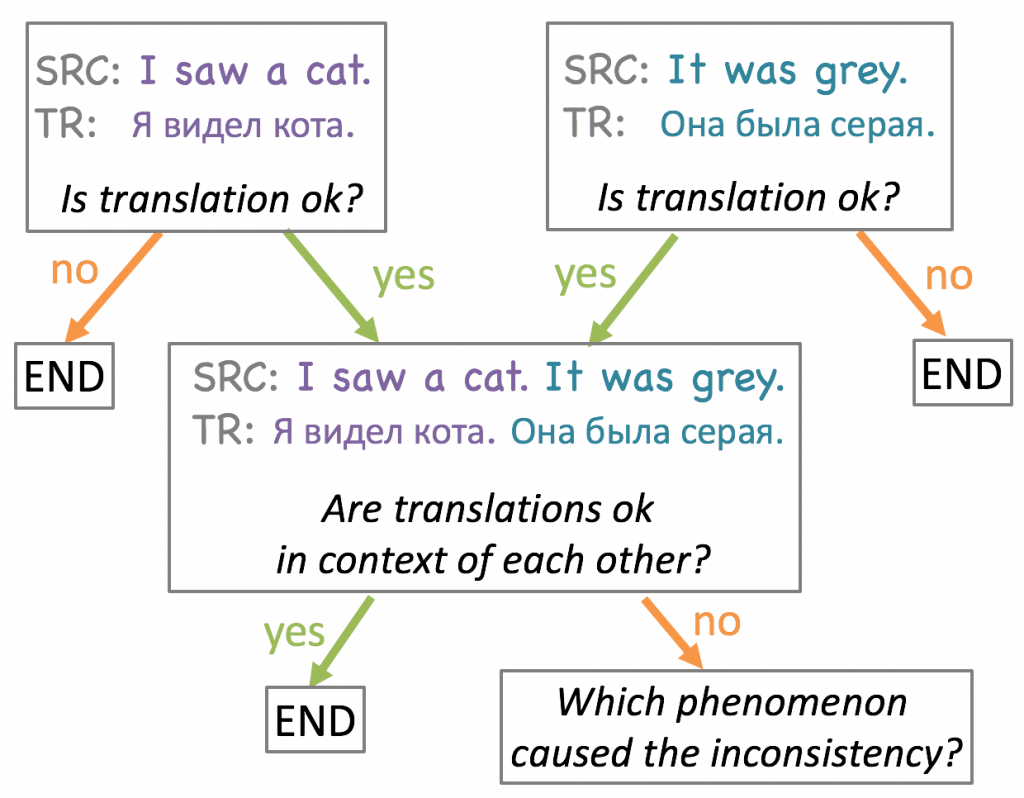
This paper by Voita et al., published at ACL 2019, starts with a human analysis to find common linguistic phenomena that result in translations that initially look good, but are inconsistent in context. For English-Russian, Voita et al. identify deixis, ellipsis, and lexical cohesion as frequent phenomena, and introduces test sets that are targeted to measure the consistency of machine translation output. Finally, Voita et al. propose a two-stage translation model that manages to improve translation consistency substantially with limited amounts of document-level parallel data. A follow-up paper, published at EMNLP 2019, shows that even monolingual document-level data can be sufficient to improve consistency. This is done via a monolingual repair model that post-edits the output of a sentence-level translation system.
Read more about this work in a blog post by Lena Voita (joint work with Rico Sennrich and Ivan Titov).